The growing size of datasets and deep learning models has made faster and memory-efficient training crucial. Reversible transformers have recently been introduced as an exciting new method for extremely memory-efficient training, but they come with an additional computation overhead of activation re-computation in the backpropagation phase.
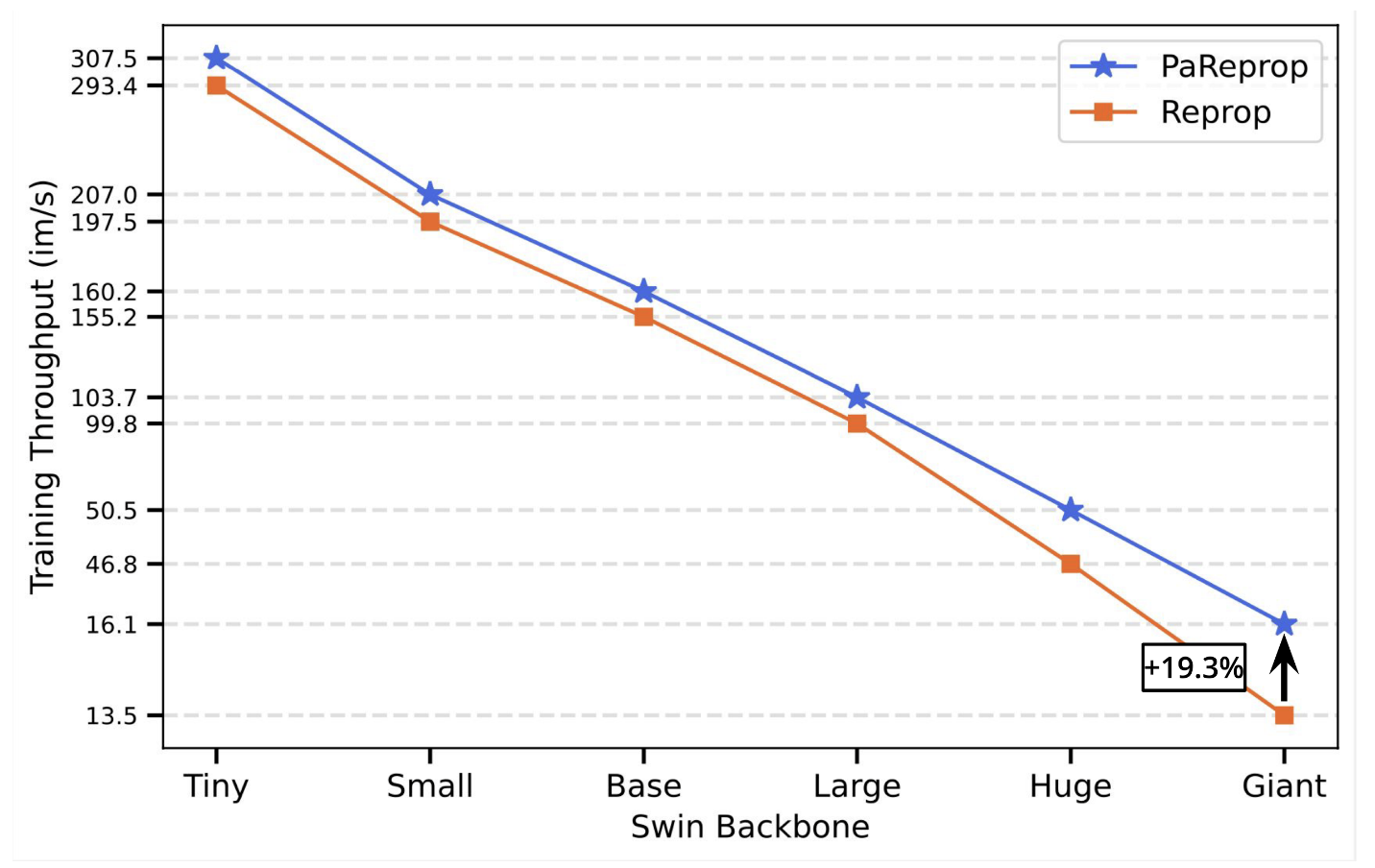
We present PaReprop, a fast Parallelized Reversible Backpropagation algorithm that parallelizes the additional activation re-computation overhead in reversible training with the gradient computation itself in backpropagation phase. We demonstrate the effectiveness of the proposed PaReprop algorithm through extensive benchmarking across model families (ViT, MViT, Swin and RoBERTa), data modalities (Vision & NLP), model sizes (from small to giant), and training batch sizes. Our empirical results show that PaReprop achieves up to 20% higher training throughput than vanilla reversible training, largely mitigating the theoretical overhead of 25% lower throughput from activation recomputation in reversible training.
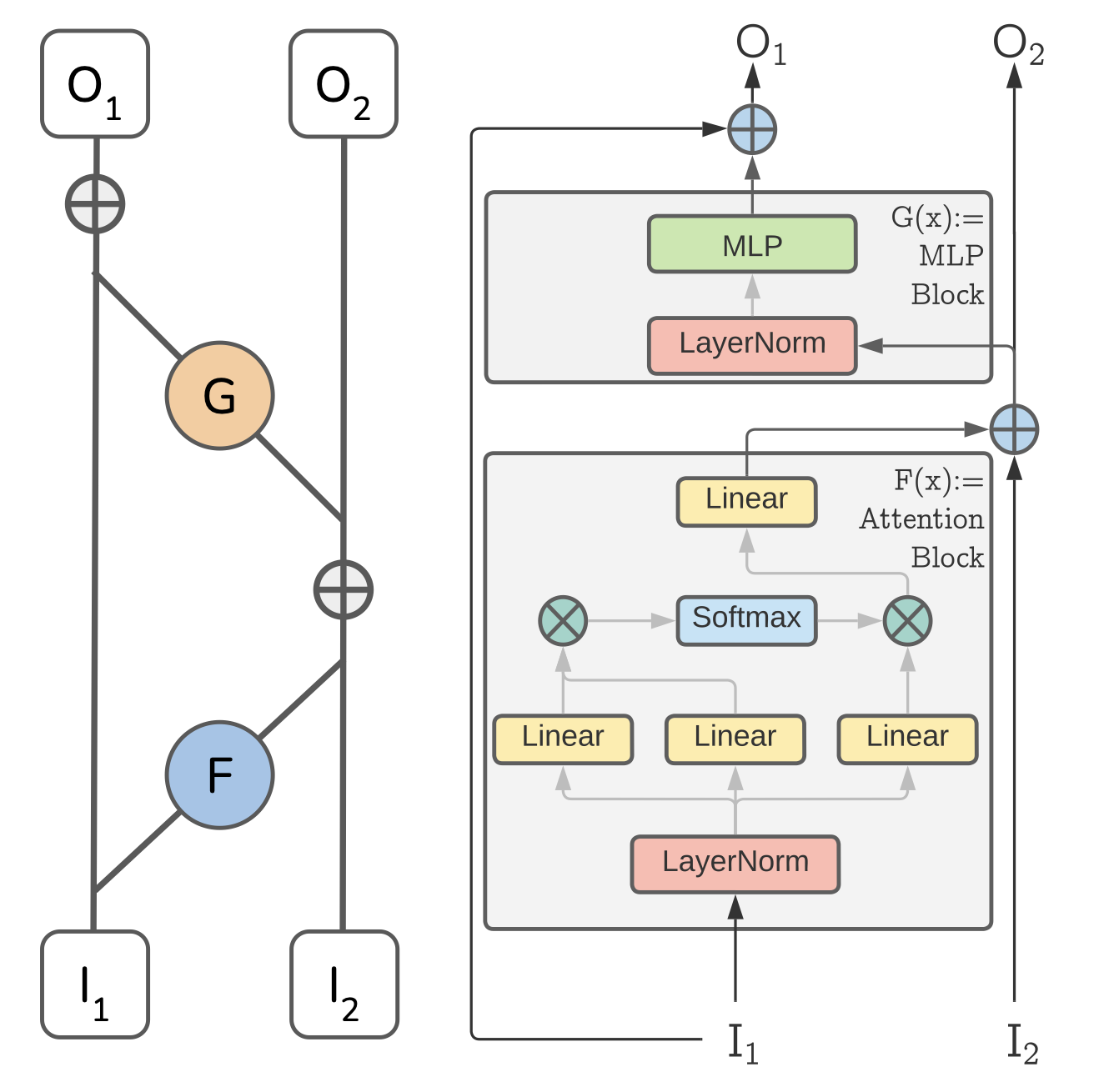
Reversible Vision Transformers are a recently proposed class of memory-efficient models which utilize a reversible transformation (left) to reduce the memory footprint of the model. They were shown to be able to achieve equal performance to their non-reversible counterparts at equal parity.
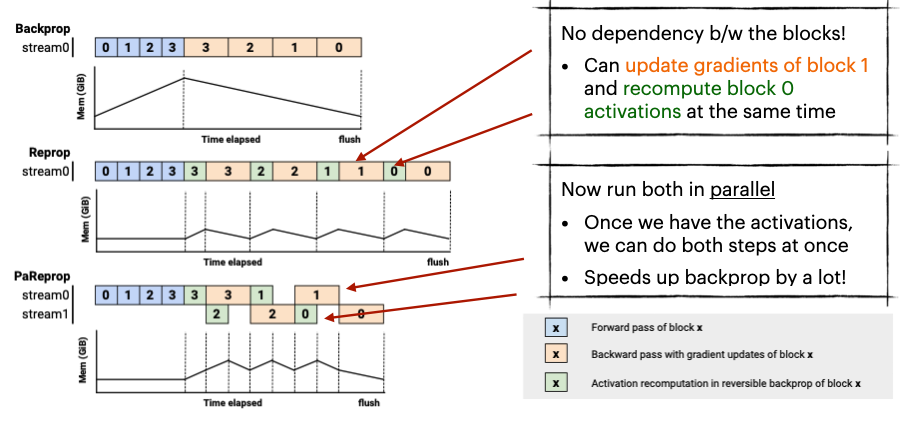
Looking at the backpropagation in detail however reveals a key issue. The reversible transformation requires the activations to be recomputed in the backpropagation phase, which is a significant overhead. Crucially, there is no dependency between the block required to update the gradients and recompute the activations of the next block. This allows us to parallelize them at the same time, and theoretically speed up reversible backprop (Reprop) to be almost as fast as normal backprop.
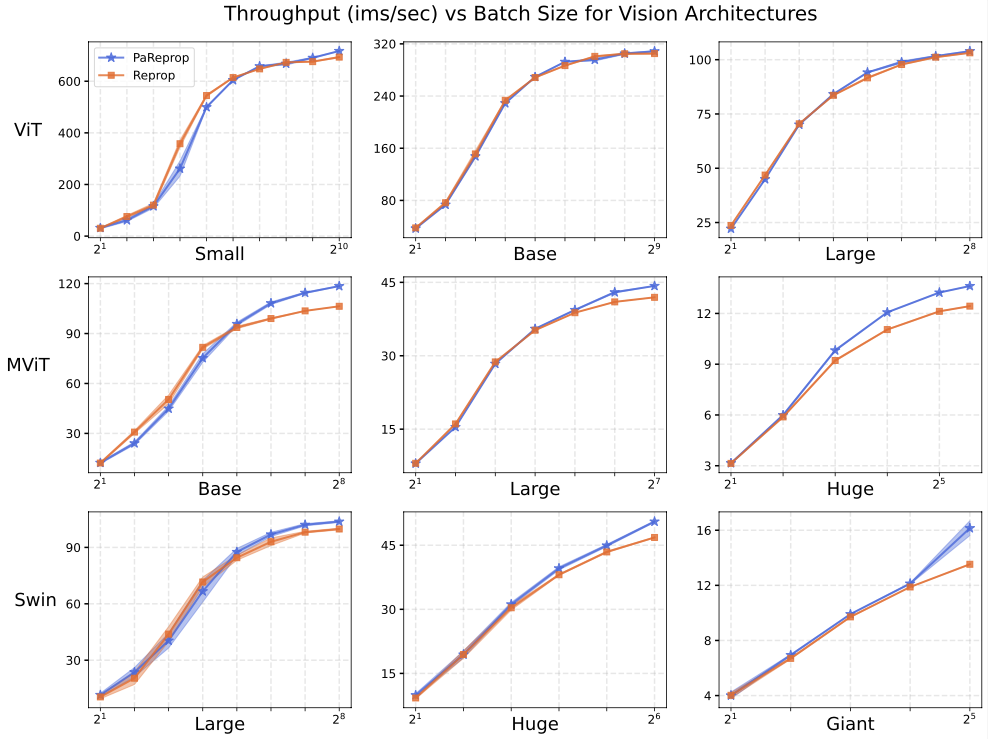
In practice, we find that our model works surprisingly well. PaReprop matches the throughput of Reprop for ViT models, while it greater improves on the hierarchical models. We hypothesize that their non-homogeneous nature is especially amenable to being sped up with parallelization.
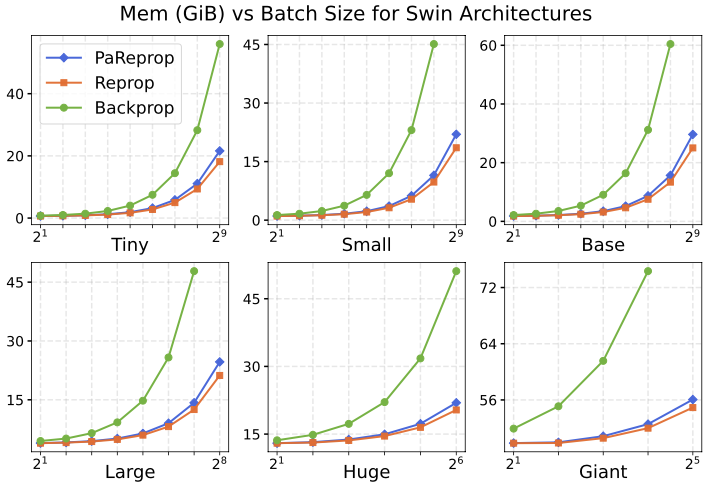
We also compare the amount of memory used by all of the methods. Both are especially memory-efficient compared to traditional backprop, and the additional memory cost incurred by PaReprop is negligible to the overall savings.
@misc{zhu2023pareprop,
title={PaReprop: Fast Parallelized Reversible Backpropagation},
author={Tyler Zhu and Karttikeya Mangalam},
year={2023},
eprint={2306.09342},
archivePrefix={arXiv},
primaryClass={cs.LG}
}