Facial Keypoint Detection with Neural Networks
Introduction
In this project, we’re revisiting Project 3 and automating the detection of facial keypoint instead of manually selecting them. We’re using convolutional neural networks in PyTorch to detect them and pulling data from two different datasets: the IMM Face Database and the ibug face in the wild dataset. Each part will slowly build up to our final model.
Part 1: Nose Tip Detection
For part 1, we perform nose tip detection with a simple CNN without any data augmentations as a first step. I implemented the dataloader, the model, and the training loop from scratch. Here are some examples of training images from my dataloader.
 Four sampled images from my training dataloader.
Four sampled images from my training dataloader.
My CNN architecture was as follows:
- Input: A grayscale image of size 80 by 64
- Conv1: 16 filters of size 3x3, with stride 1 and padding 1 to keep the size of the image constant.
- Conv2: 32 filters of size 3x3, with stride 1 and padding 1.
- Conv3: 64 filters of size 3x3, with stride 1 and padding 1.
- Conv4: 64 filters of size 3x3, with stride 1 and padding 1.
- Linear1: A fully connected layer with 64 * 5 * 4 input neurons and 64 output neurons.
- Linear2: A fully connected layer with 64 input neurons and 2 output neurons.
After every conv layer, I applied a ReLU and used a max pooling layer to reduce the size of the image in half in each dimension, so that the max pooling is responsible for all spatial reduction.
To optimize, I used Adam with a learning rate of 1e-3 and MSE as my loss. Here are training curves for this experiment (ignore the RMSE label, it is MSE).
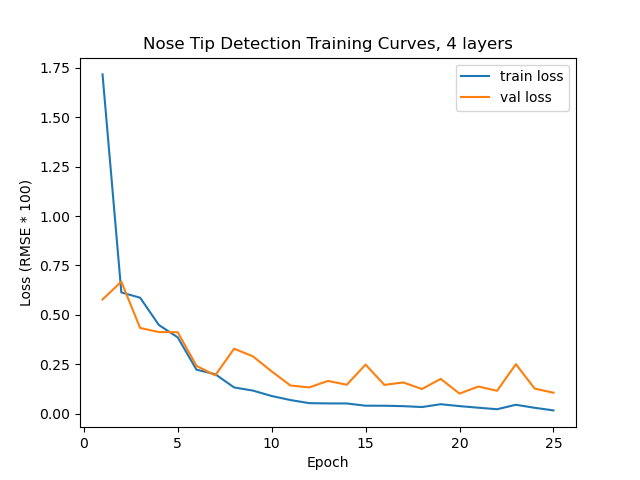 Training curves from this training run.
Training curves from this training run.
Here are some visualizations of our predicted keypoints, both good and bad, (in red) against the ground truth (in green).
 Positive predictions.
Positive predictions.
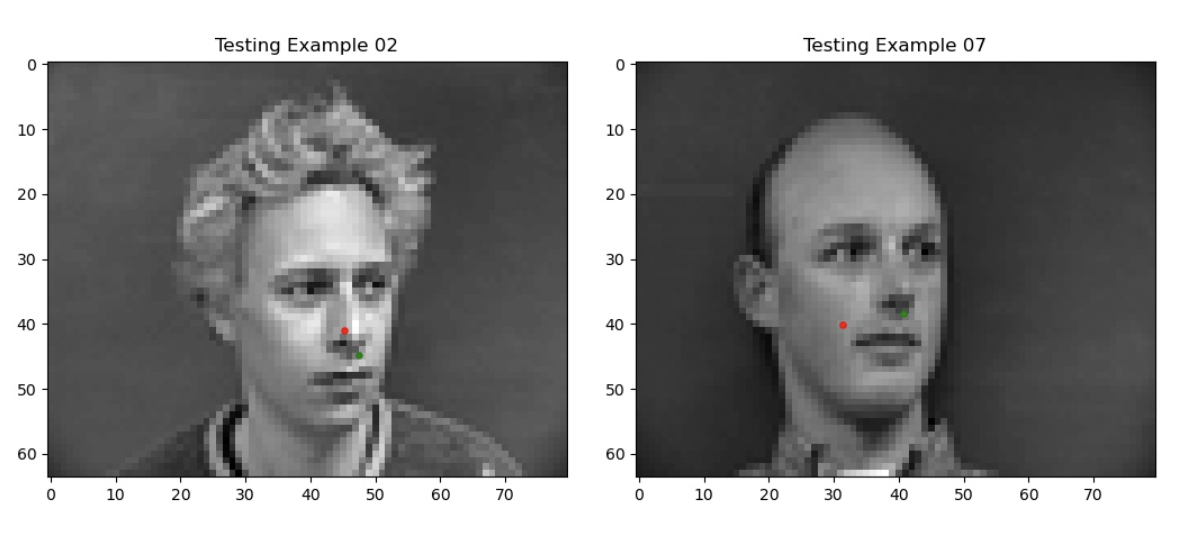 Negative predictions.
Negative predictions.
My guess is that because the orientations of the faces are different, the nose tip is not as easily detected (although there are forward facing faces which also don’t get easily detected).
Finally, I tried messing around with two other hyper parameters, namely increasing the learning rate to 4e-3 and replacing the first two 3x3 convolutions with 5x5 convs (and changing the padding to 2 accordingly so that the image shape doesn’t change). Here are the training curves from those experiments, but neither did as well as my original. I suspect the 5x5 convs are hard to learn with such little data and too aggressive for small images, and the learning rate as well is too high for the data.
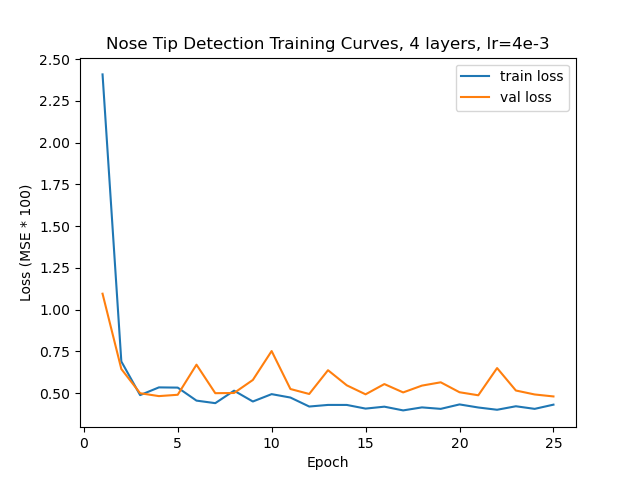 Training curve for increased lr run.
Training curve for increased lr run.
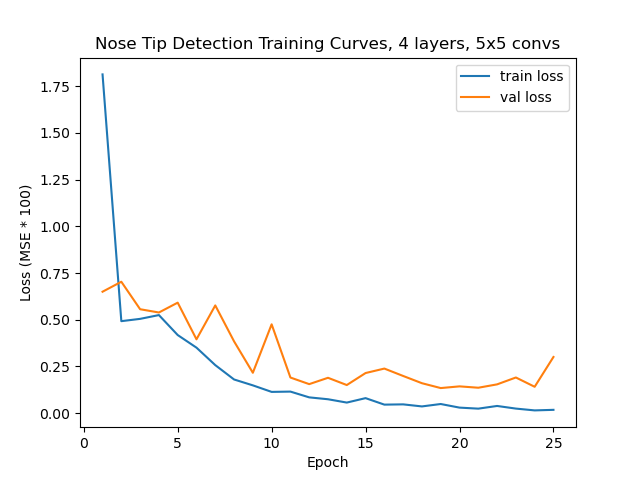 Training curve for 5x5 conv layer experiment.
Training curve for 5x5 conv layer experiment.
Part 2: Full Facial Keypoints Detection
For the next step of the project, we tackle a similar problem as part 1, but instead try to predict all of the keypoints. We will use the same architecture as before, but with a few more conv layers.
To prevent overfitting, we introduce a few data augmentations to our training data, namely color jittering and random affine transformation (rotations and translations). I originally also used horizontal flipping, but a correct implementation was more tricky than I thought so I took it out later (see later discussion on this). Here are a few samples from my training loader.
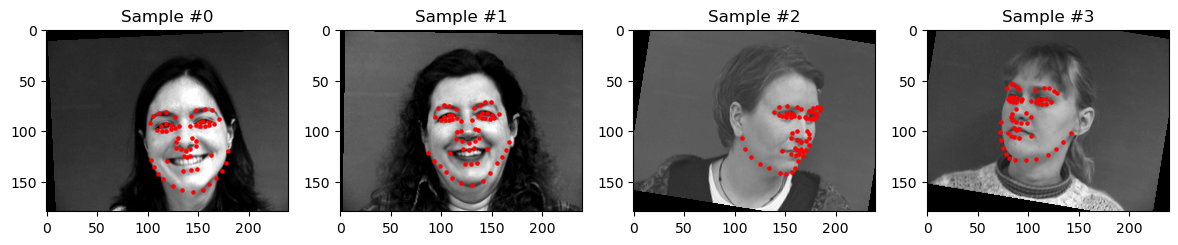 Four sampled images from my training dataloader.
Four sampled images from my training dataloader.
It was tricky creating augmentations since we need to apply the same augmentations to the keypoints. I used the get_params() method from the transforms module to obtain the parameters to manually apply it to the keypoints.
My architecture is very similar to the previous part’s, but with 5 conv layers.
- Input: A grayscale image of size 160 by 120.
- Conv1: 32 filters of size 3x3, with stride 1 and padding 1.
- Conv2: 32 filters of size 3x3, with stride 1 and padding 1.
- Conv3: 32 filters of size 3x3, with stride 1 and padding 1.
- Conv4: 64 filters of size 3x3, with stride 1 and padding 1.
- Conv5: 64 filters of size 3x3, with stride 1 and padding 1.
- Linear1: A fully connected layer with 64 * 20 * 15 input neurons and 2000 output neurons.
- Linear2: A fully connected layer with 2000 input neurons and 2 * 58 output neurons for keypoint prediction.
I took inspiration from the recipe provided in CS 231n [1] and followed this pattern for mixing convs, relus, and max pooling.
INPUT -> [CONV -> RELU -> CONV] -> [CONV -> RELU -> CONV -> RELU -> POOL]*2 -> FC -> RELU -> FC
To help the model learn more easily, I also initialized the bias of the final linear layer according to a Normal(0.5, 1/sqrt(2000)) distribution since most of the points are around the center of the face (a tip off to Andrej [2]). You can see an example of the training process where the initial points start in the middle due to this in the below video where I was debugging horizontal training.
As you can see, the points begin to cluster around the middle. This is because the points were being mathematically flipped, but not re-assigned to their designated spot. In other words, the left mouth corner was being sent to the right mouth corner half of the time, so the model learned to output an average to mitigate loss. I felt like fixing this would be more trouble than it was worth, so I simply took it out (and as it turns out, the ibug dataset provides this augmentation out of the box!).
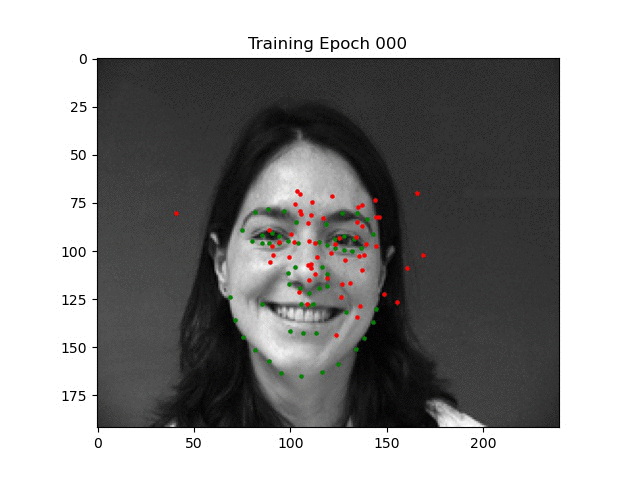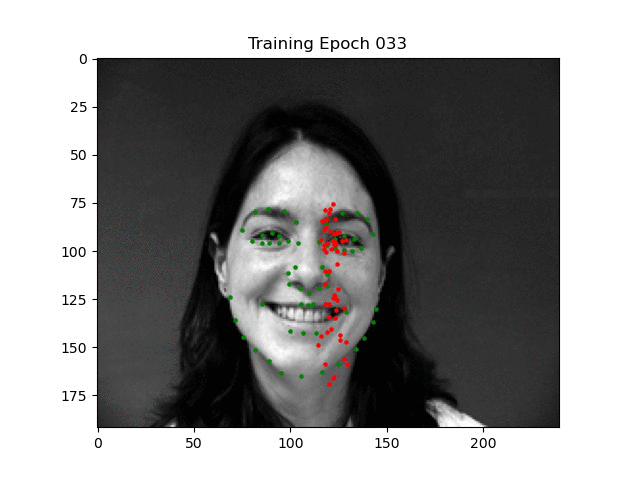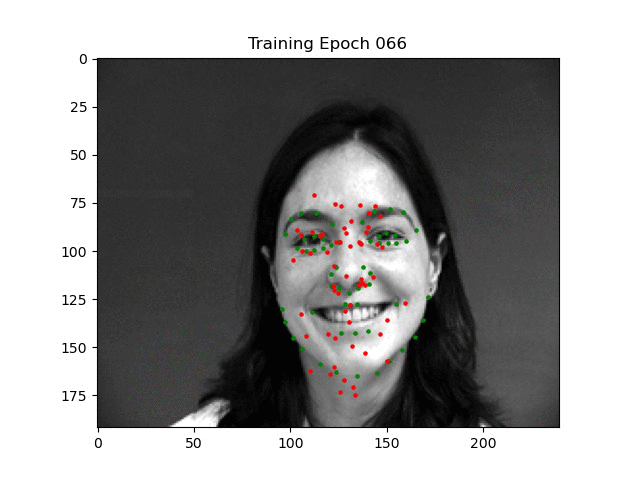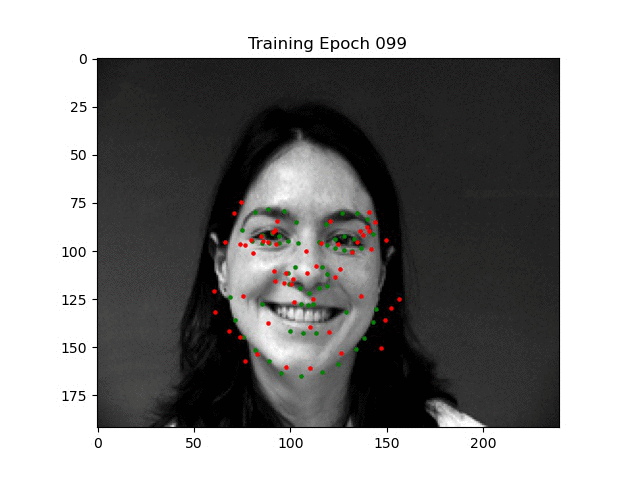 Visualization of training dynamics when using horizontal crops (incorrectly).
Visualization of training dynamics when using horizontal crops (incorrectly).
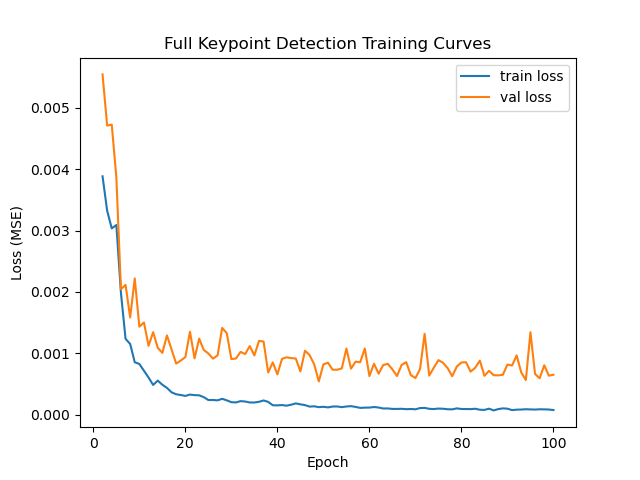
To optimize, I used Adam with a learning rate of 1e-3 w/ a batch size of 8 for both training and validation and MSE as my loss, and ran it for 100 epochs. Originally I multiplied my learning rate by sqrt(8) as is typically advised when increasing batch size, but it led me to bad results where my model would output a face average for every datapoint (that was a nasty bug to figure out!). Here are training curves for this experiment.
 Training curves from this training run.
Training curves from this training run.
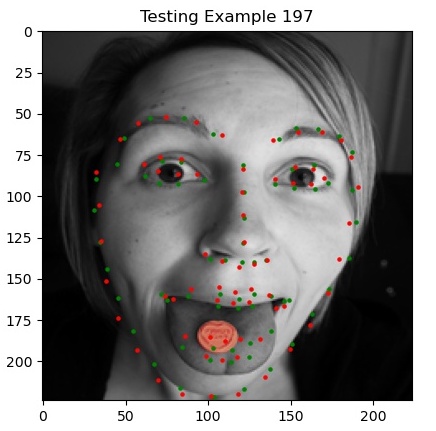
This model gets a final validation MSE of 0.00054, which is pretty good. Here are some visualizations of our predicted keypoints (in red), both good and bad, against the ground truth (in green).
 Positive predictions.
Positive predictions.
 Negative predictions.
Negative predictions.
I suspect the negative predictions happen because of how heavily different some of the orientations of the faces are, as well as extra obstructions in the picture. You can see when the model is confused it simply outputs the average face to minimize loss.
Finally, here are the visualizations of my conv1 filters. They are hard to understand, so if I wanted to make them more understandable, I would have to see how they affect certain types of inputs. However, we can see generally there are trends of light and dark that make them look for patches or edges in the input image. For example, Filter 1 and 25 are selecting for strong points in corners.
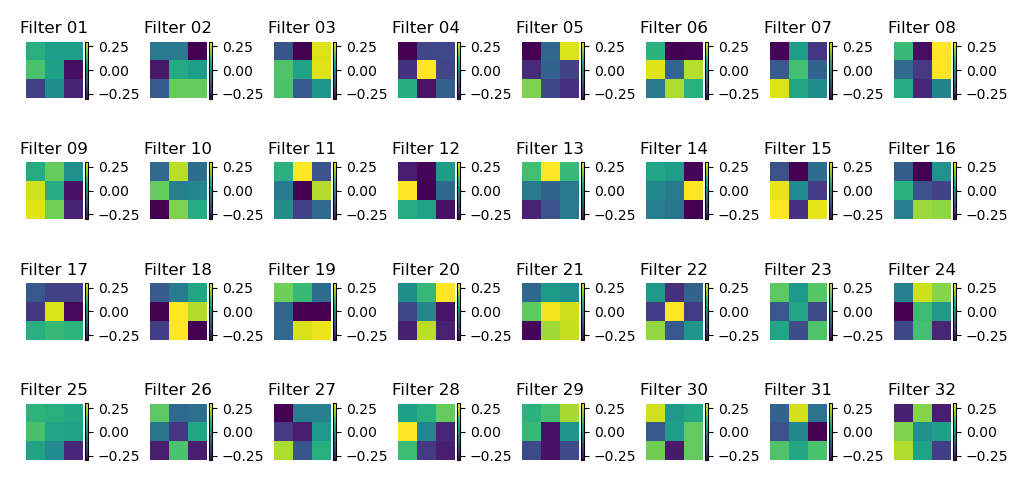 Visualization of the filters in the first convolutional layer.
Visualization of the filters in the first convolutional layer.
Part 3: Train With Larger Dataset
Finally, we get to the meat of the project where we train our model on the iBUG dataset of 6666 images of faces in the wild to learn to detect keypoints. We’ll swap out our model for an established pre-trained one (namely Wide Resnet-50), change out loss function, and make a few other minor changes to get a pretty good initial result.
My first submission to kaggle got a score of 7.24259, placing me 10th at the time.
As is standard fare by now, we have to make a new dataloader for this dataset. The main new addition is that we are only loading crops of the input images based on the bounding boxes. The bounding boxes given to us by the dataset were pretty bad and generally led to the extreme labels being about -1.25 to 1.25 post normalization. So I decided to increase the bounding boxes by 25% on each side (50% in total), taking care not to size past the actual image. This was pretty significant in placing most landmarks within the box, as you can see below.
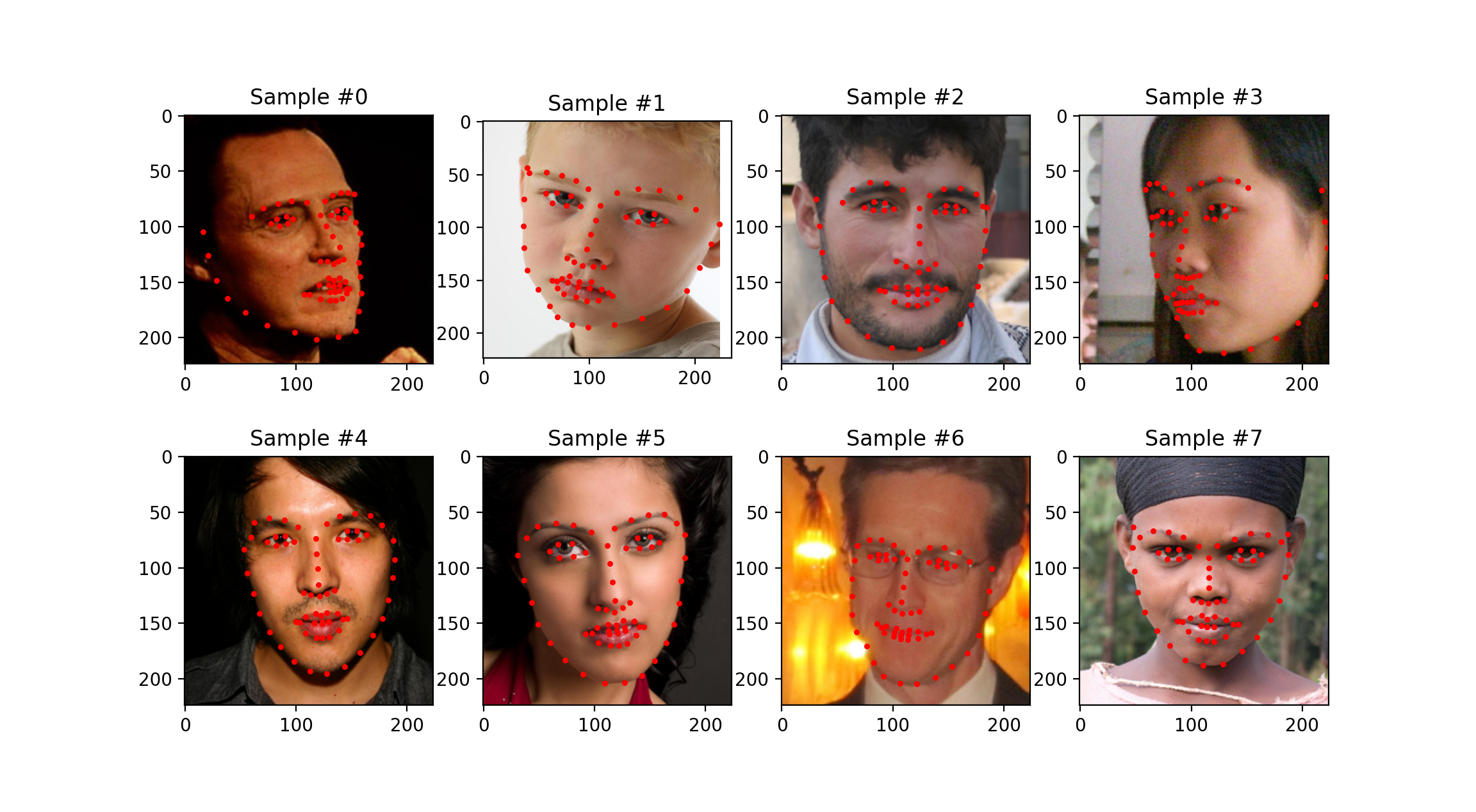 Some sampled images from my training dataloader with an enlarged crop.
Some sampled images from my training dataloader with an enlarged crop.
My architecture this time is simply a Wide Resnet-50, which is a Resnet-50 with all the internal 3x3 convs twice as wide (i.e. double the number of filters), with the last linear layer changed to have 2 * 68 output neurons, along with the 0.5 bias initialization I mentioned in the last section. It has 67,112,904 parameters, most notably of which is an average pool at the end (I’ll discuss this later).
I was able to train this with batch size 64 with a learning rate of 3e-4 (adjusted from before) for 30 epochs. I switched to using a Smooth L1 loss for training since I felt it better tracked the final objective, which was mean absolute error. I also tracked an adjusted mean absolute error in absolute pixel space to get a sense of how well my model might do on the Kaggle test set.
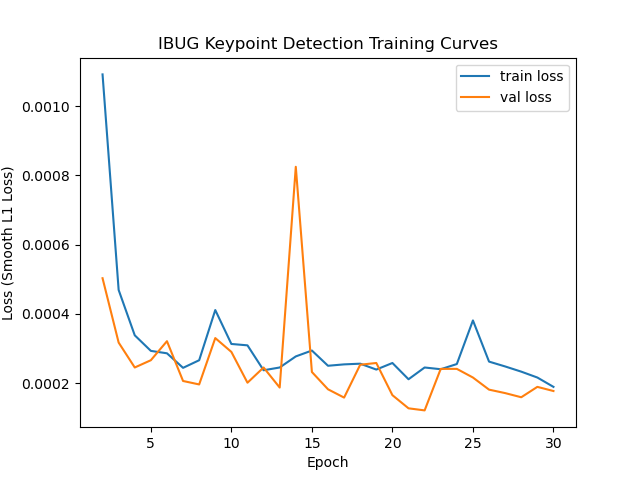 Training and Validation losses during this training run.
Training and Validation losses during this training run.
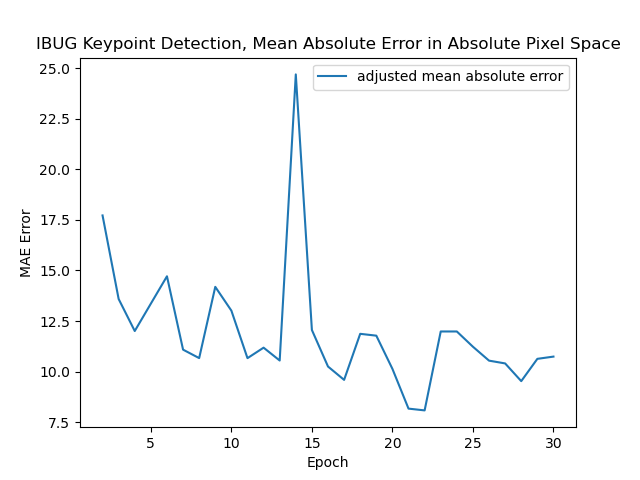 Mean absolute error on the validation set during training.
Mean absolute error on the validation set during training.
My model ends up getting a final validation L1 loss of 0.000121, which corresponds to an adjusted validation MAE of 8.079482. This ended up being higher than the test validation. One thing to note is that the train and validation loss intermingle, and particularly the validation loss is not often higher than the train loss. I attribute this mainly due to batchnorm, which gets turned off during evaluation and so decreases the error ever so slightly. In fact, when I disabled batch norm, my plots look quite reasonable and normal.
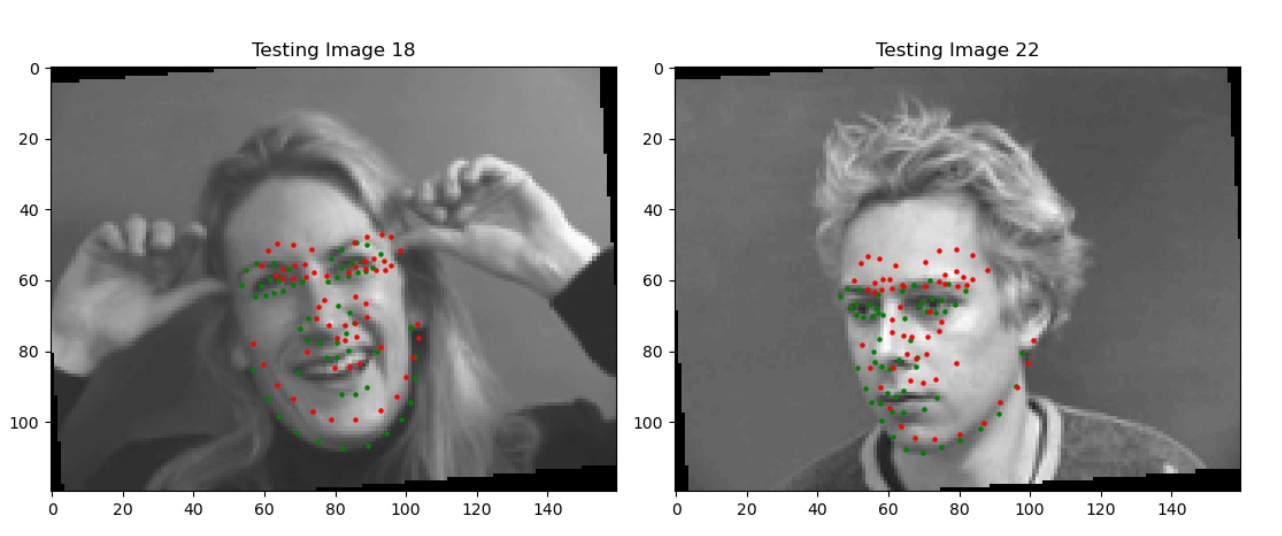
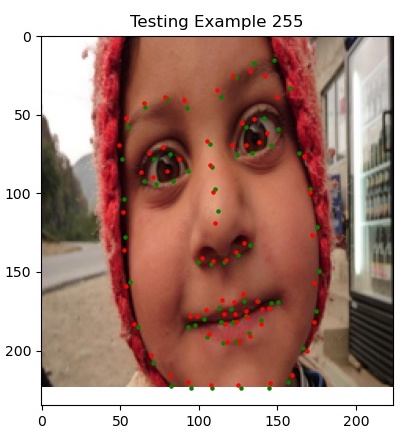
Here are some sample predictions from my model on the test set (click to zoom in!).

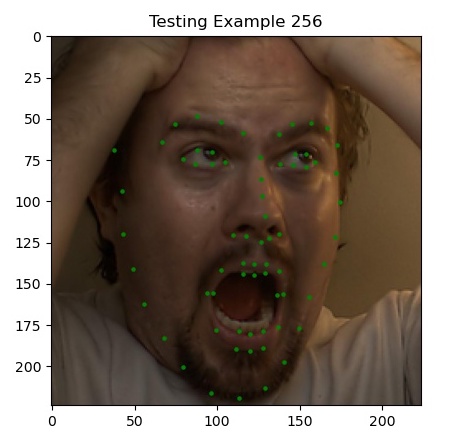
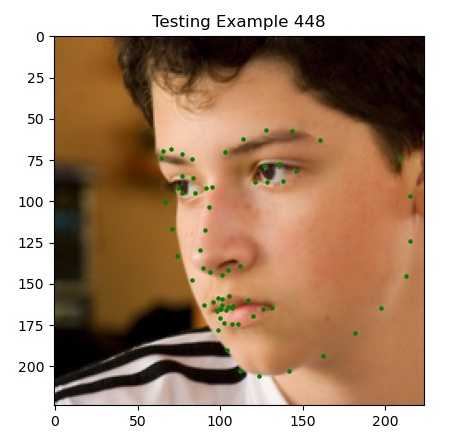
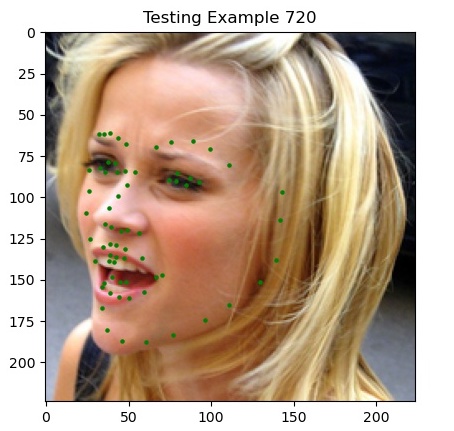
Most notably, we’re finally doing well on faces that are oriented away from the camera and at angles, which our previous two methods struggled with. I’d argue that the last picture (example 720) is actually predicting where her jaw is behind her cheeks.
Finally, I tested my algorithm on a few fun photos. Here are all the original photos and keypoints side by side.
 Picture of 5th grade me taken with a potato.
Picture of 5th grade me taken with a potato.
 Rude of my algorithm to predict my chin like that.
Rude of my algorithm to predict my chin like that.
 Picture of a good boi.
Picture of a good boi.
 Pretty good for a non-human.
Pretty good for a non-human.
 Kid from the Vine `Kid on Crack`.
Kid from the Vine `Kid on Crack`.
 Even the algorithm thinks he's on crack.
Even the algorithm thinks he's on crack.
 Zack Fox and Kenny Beats.
Zack Fox and Kenny Beats.
 Still the same Zack Fox and Kenny Beats. Yep.
Still the same Zack Fox and Kenny Beats. Yep.
Bells and Whistles
There were a few things I did for my Bells and Whistles, mostly revolved around creating a new architecture but also exploring what techniques would make my performance better. In the end, my original submission was the best so all the extra modifications didn’t help. Perhaps I needed more time to tune them successfully.
Minor Improvements
Immediately there were a few minor improvements I thought of making. The first was to normalize the color channels by the Imagenet mean and std to make the data standard normal, i.e. using mean = [0.485, 0.456, 0.406] and std = [0.229, 0.224, 0.225]. This is a pretty standard normalization for images, and considering I was using pre-trained weights, I thought this would improve performance over the simply min/max normalization of dividing by 255 and subtracting 0.5. However this didn’t improve my performance when I tried, so I might have needed more tuning.
I also tried using a [95%, 5%] training-validation split instead of [80%,20%] as I had before, but this also didn’t lead too better results (at least when compounded with the above modification). The extra signal from the validation set for picking the best model probably helped my original model generalize better.
Pixelwise Classification: Pixel U-Net
I thought it would be fun to try and implement keypoint detection using a pixelwise classification set up instead. I was inspired by the PSMNet/GCNet family of depth estimation models when creating my architecture (see [3],[4]). As suggested in the spec, instead of connecting our CNN to a linear output (destroying all spatial information with an average pool as well!) and directly regressing the keypoints, we can instead predict how likely each pixel is to be a keypoint.
The key problem is how we’re going to recover the original input space in order to report predictions on, since we downsample our image many times. Using a U-Net architecture with its encoder-decoder architecture turns out to work perfectly for this, as segmentation (it’s original intended task) is pretty similar to what we’re trying to do. This allows us to work on the image efficiently at a smaller scale for feature extraction, and gradually incorporate information at different scales to get a final prediction.
Following all this, our output will be some tensor of shape [B x ? x H x W], where ? is the number of output channels, and H=W=224 in our case. We need some method now of predicting the likelihood of each pixel being a keypoint. The spec suggests using 2D Gaussians to turn the ground truth into heatmaps (which is quite efficient), but I decided to do what most modern stereo depth estimation models do. I constructed a cost volume of size [B x 68 x H x W], each channel corresponding to a keypoint, and applied a softmax to each channel to get a probability distribution for the keypoints over the pixels. I then aggregated the probabilities with their respective width/height values to get a final pixel prediction for each keypoint, both height and width, for an output of [B x 138]. This was then trained with a smooth L1 loss to encourage sparsity. Here’s a gif of my training dynamics trying to fit to a single image.
I dub this architecture Pixel U-Net, since it’s a U-Net modified for pixelwise classification. It took a big of debugging to get everything to line up, but it was quite simple since I just had to make a custom module for the softmax and aggregation. Some sources online debating if softmax is necessary for these types of tasks, but in my case the softmax was extremely important, as otherwise we’d be summing 224*224 values around 0.5 to get our loss, making it very hard to learn.
I trained it very similar to before, except using a learning rate of 3e-3. Here are my training curves, with the final adjusted MAE being 7.8349 (lower than my previous algorithm, but does worse on Kaggle).
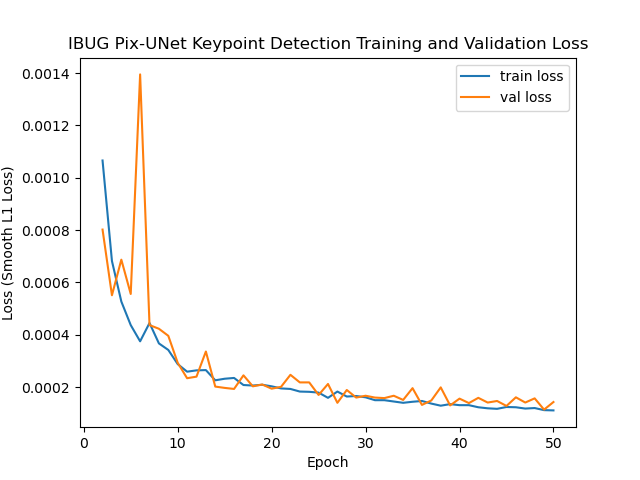 Training and Validation losses for Pixel U-Net.
Training and Validation losses for Pixel U-Net.
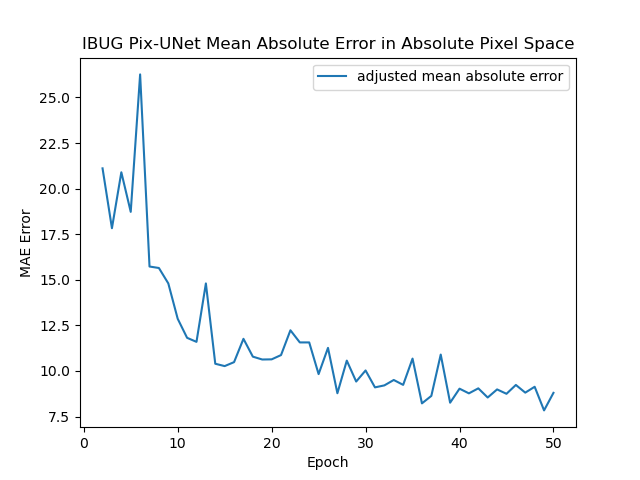 Mean absolute error on the validation set for Pixel U-Net.
Mean absolute error on the validation set for Pixel U-Net.
Here are some example outputs. Notice how they all seem to be slightly off from the true keypoints, but otherwise are all virtually around the right area. The model might have needed more training or some learning rate decay/restarts (this was my first attempt at a long run, so not tuned at all).


References
- CS 231n CNN notes: Link
- A Recipe for Training Neural Networks, Andrej Karpathy blog: Link
- End-to-End Learning of Geometry and Context for Deep Stereo Regression (GC-Net): Paper Link
- Pyramid Stereo Matching Network: Paper Link, Code Link